Insights into Developing an AI-Powered Bot!

I have developed and deployed a Telegram Bot that is powered with OpenAI capabilities to help administrate the SCS Cyber Community Telegram Supergroup . It was trained with closed to approximately 1000 data points using the GPT 3.0 Ada as our base model to aid moving messages according to their classifications to the right Topics.
If you would like to read the introductory post, please visit this link here .
For this post, I will share some considerations when developing the Telegram Bot. For example, establishing a need for software system, ascertaining suitability of AI, and defining acceptable cost. This Telegram Bot was found to be an ideal project to apply AI!
Furthermore, I have also shared on a) why GPT 3.0 Ada was chosen as the base model, b) challenges of using OpenAI, and c) some success stories.
Lastly, on my personal reflection, I would like to emphasise the importance of a) NOT following the crowd blindly, b) NOT having to over engineer, and c) defining measurements of success.
“The journey starts with what we can do, but it ends with what we can do to achieve their goals.”
This Telegram Bot project is my personal project and initiative as a member of the cyber community. Any vulnerabilities identified would be directly attributed to my work, and I will be glad to fix any reported vulnerabilites soonest. If you believe you have found a security vulnerability in any of my repositories, please report it to me. I will be more happy to fix it with your help.
Please do not report security vulnerabilities through public GitHub issues, discussions, or pull requests. Instead, please send an email to opensource.report.vulnerability@gmail.com
Please include as much of the information listed below as you can to help us better understand and resolve the issue:
- The type of issue (e.g., IDOR, SQL injection, or cross-site scripting)
- Full paths of source file(s) related to the manifestation of the issue
- The location of the affected source code (tag/branch/commit or direct URL)
- Any special configurations or pre-requisites that are required to reproduce the issue
- Step-by-step instructions to reproduce the issue
- Proof-of-concept or exploit code. It will be great if it is available. :)
- Impact of the issue, including how an attacker might exploit the issue
This information will help me to triage your report more quickly.
Quick Introduction
For this post, we will dive deeper, under the context of this project, to discuss about some of the considerations when designing an AI system, the Model Training process, as well as the challenges and success stories.
System Design Considerations
Firstly, we have to ask ourselves if we are solving the right business problem. This is even before applying AI or OpenAI. Sometimes, as an engineer, we could be overzealous with latest technologies (e.g. AI, Blockchain, Homomorphic Encryption, Confidential Computing, etc.), and would want to try applying them without having a deeper analysis on how these techologies can be used to benefit our business relevantly. 😁
Hence, after listening to all the hype, I will get some cold drink 🍹 to cool myself down, and take a step back to assess if I am solving a relevant problem that will deliver impact to my users. The last thing that I want is to have a solution looking for a problem to solve!

Secondly, there is no silver bullet! While AI looks magical where ChatGPT seemed to be able to interact and solve many hard problems and AlphaGo could win the world champion in Go, AI still cannot solve all problems! This is inherently because AI will sometimes make mistakes. It makes decisions largely by maximizing the probablility of success. E.g. Finding a threshold that separates the two overlapping Gaussian curves will always result in having False Positives and False Negatives (see diagram below from ResearchGate).

In cases where no mistakes can be afforded, especially without supervisors to validate, simple automation may sometimes be a wiser choice. I probably wouldn’t trust an AI system (yet) to perform surgery on me, without having a doctor to make the surgical decisions!
Thirdly, have we over engineered? Sometimes using AI/ML could be an overkill solution. Could it a problem that could be solved through a simple programmatic control flow? Or could a rule-based system solve the problem effectively? Will further refining of the ML model to increase its accuracy from 85% to 90% (and above) changes the users’ experience?
Engineering resources are scarce. If we do not need to further engineer, should we channel our energy to deliver more value to our users?

These considerations probed me to assess further if the Telegram Bot is a suitable use case.
-
Is it a problem that is painful enough to solve through engineering?
Yes, it is a very painful process for me and my administrators to forward messages that are sent to the wrong topics, and this operation has no end-date. 😭
-
Can I live with misclassification of messages by AI?
Yes, it is ok for some of the messages to be classified wrongly. The Telegram Bot has to be design to minimise the impact of wrong classification by its AI component as part of the program flow. 😝
-
Is AI the only way to solve the problem?
Yes, there is a need to use natural language processing techniques to analyse the messages as they are inherently undefined. 😎
-
Is this implementation going to be affordable?
Yes, it should be an affordable implementation. On an average day, there is around 20 messages sent to the group. Considering that Ada model would cost “only” $0.0004 / 1K tokens, the cost should be affordable, especially for a community volunteer like me where I have to consider cost seriously. 💲
-
Do I have optimal amount of data to train the model?
No. Despite that I am unable to collect optimal number of samples for each class of data, I have a fair amount of data to start off with. This at least not a cold start.
Overall assessment, it scores around 4.5 out of 5 against the list of considerations. It is probably a problem worth trying!
Why GPT 3.0 Ada?
Well, it is often counter intuitive on why are we not using the latest and greatest, i.e. GPT 3.5 Turbo and GPT 4.0. Truth to be told, we couldn’t. As of date, only GPT 3.0 models are available for fine-tuning . 😝
More importantly, even if we could, we wouldn’t want to. For our use case, we do not need a more capable model that is trained with latest data. What we need is a cheap and fast way to achieve our task, i.e. classifying selected simple text messages.
Among all GPT 3.0 models, Ada is cheapest and fastest. It is also good enough for our use case as recommended by the documentation
.
Classifiers are the easiest models to get started with. For classification problems we suggest using ada, which generally tends to perform only very slightly worse than more capable models once fine-tuned, whilst being significantly faster and cheaper.
As of date, the price for fine-tuning the models can be found here .
| Model | Training | Usage |
|---|---|---|
| Ada 🏆 | $0.0004 / 1K tokens | $0.0016 / 1K tokens |
| Babbage | $0.0006 / 1K tokens | $0.0024 / 1K tokens |
| Curie | $0.0030 / 1K tokens | $0.0120 / 1K tokens |
| Davinci | $0.0300 / 1K tokens | $0.1200 / 1K tokens |
The Beta Telegram Bot has been deployed for two weeks and only cost approximately USD $0.15. 🤑 Seems like we have made a right decision!
Model Training Process
Getting data to refine the model is one of the hardest problem, especially for a new system like ours. It is akin to a “which comes first problem” - Chicken or Egg. Without an existing system, there is no data. If there is no data, training can’t be done. When training cannot be done, there will be no system. 😹

To do this training, I used the data that was publicly posted in the chat group. To achieve this, I have written another Telegram client using Telethon to collect the historical data, and create Prompts with labels. These Prompts were then manually verified. Below is a sample script which you can explore using. You can get your Telegram App ID and Telegram App Hash through following the link here .
Most of time spent during development was to find out where to get the Topic ID! There wasn’t much resources on how to manage a Supergroup programmatically. Thankfully, my malware reverse engineering experience has helped me a great deal in debugging to uncover the field that corresponds to the Topic ID, i.e. message.reply_to_msg_id, which is pretty unintuitive.
|
|
If you have noticed, the Prompt ends with “\n\n###\n\n”. It is because it follows the guideline on how to design a classifier.
In classification problems, each input in the prompt should be classified into one of the predefined classes. For this type of problem, we recommend:
- Use a separator at the end of the prompt, e.g.
\n\n###\n\n. Remember to also append this separator when you eventually make requests to your model.- Choose classes that map to a single token . At inference time, specify
max_tokens=1since you only need the first token for classification.- Ensure that the prompt + completion doesn’t exceed 2048 tokens, including the separator
- Aim for at least ~100 examples per class
- To get class log probabilities you can specify
logprobs=5(for 5 classes) when using your model- Ensure that the dataset used for finetuning is very similar in structure and type of task as what the model will be used for
However, for this project, even though I have collected approximately 1000 samples, I couldn’t follow a majority of the guideline! 😮 This was due to the uneven distribution of the limited data collected. This would imply that I would need to be more “lenient” in the Telegram Bot’s decision making process. Probably, it would need at least another year or two to collect adequate data. By then, my brain would probably be already “fried” 🍳, due to manual administration!
| Class | Number of Samples |
|---|---|
| Others | 719 |
| News | 177 |
| Trainings | 70 |
| Jobs | 61 |
| Articles | 58 |
As part of the Prompt Engineering process, I have reviewed about 1000 Prompts to validate their labels, manually.
As part of the troubleshooting process, I used the OpenAI Playground test its responses using the refined model and relevant settings. It is pretty impressive to see that despite the lack of data, its performance is still generally acceptable.
Applying OpenAI Classifier in the Telegram Bot
From the code in the SCS’s Telegram Bot
that processes news posted in the “News Topic”, you may noticed that the algorithm is generally more “lenient” where it is ok if the messages were classified as news or articles. This is because the real bug bear is: members of the Supergroup having endless discussions in the “News”, “Jobs”, or “Trainings” Topics. This clutters the views and affects the user experience for other members.
|
|
Some Challenges When Using OpenAI
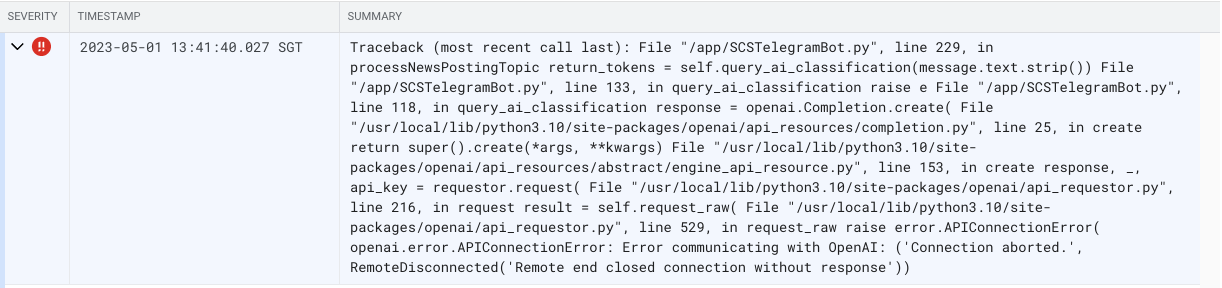
Free plan does not guarantee availability! 😭

“Error, error, error!” I have been troubleshooting for a very long time on why is there inconsistency and reliability issues with some of the API connections. I have finally realised that it was because I did not subscribe to the ChatGPT Plus service! See below for the consequence for not paying. 💸
Well, I think I will just have to live with some messages not being processed than to pay USD 20 (˜SGD 27) per month for ChatGPT Plus service. With that money, I can use it to eat 5 bowls of my favorite “Ban Mian ”. 😼 If you have not tried Ban Mian, I strongly recommend you to visit Singapore to try it out! 😁
Another challenge. Below depicts a link that was posted to the “Articles” Topic. However, it was misclassified as news and was forwarded to the “News” Topic instead. On a first glance, with limited information, i.e. only the link, it does look like a link to some news!

Hence, I visited the link to check its content. Indeed, it was an article and can only be verified when reading deeper into the page (see below). On this, probably not much harm was done. 😅

That said, the Telegram Bot did serve its purpose in most cases. For example, cyber security related questions were posted in the “Reports and Articles” Topic and was forwarded to the “Cyber Discussions” Topic! 🙌

Personal Reflection
Firstly, let’s not follow the crowd blindly.
We would probably want to spend more time investigating if the problem is valid worth solve. Additionally, we would also want to check if it has a scope for AI before investing into exploring AI.
Inherently, AI can make mistakes. Hence, AI is useful when it is used to build an assistant or make low risk decisions.
Secondly, let’s not over engineer.
While we can use the best possible model as a base training model, it may not be the most ideal model in terms of its cost effectiveness and performance!
Separately, in many occasions, we may not have the most optimal amount of data. But, do we have enough data to achieve the business goals? Probably augment with some engineering efforts, we could still meet the business objective?
There is no shame of using rule-based engine or control-flows. At the end of the day, it is the impact to the end users that matters.
Lastly, let’s define the measurement of success.
Is it high accuracy or F1 score? Is it that the system must labelled “AI”, “Blockchain”, or “Homomorphic Encryption” ready? Or is it just simply the satisfaction level of the users?
“The journey starts with what we can do but ends with what we can do to achieve their goals.”
Special thanks to my wife and son for giving me time to work on this project.
If you like this post, please share it to reach a wider LinkedIn community.